Presidio PII Masking with LiteLLM - Complete Tutorial
This tutorial will guide you through setting up PII (Personally Identifiable Information) masking with Microsoft Presidio and LiteLLM Gateway. By the end of this tutorial, you'll have a production-ready setup that automatically detects and masks sensitive information in your LLM requests.
What You'll Learn
- Deploy Presidio containers for PII detection
- Configure LiteLLM to automatically mask sensitive data
- Test PII masking with real examples
- Monitor and trace guardrail execution
- Configure advanced features like output parsing and language support
Why Use PII Masking?
When working with LLMs, users may inadvertently share sensitive information like:
- Credit card numbers
- Email addresses
- Phone numbers
- Social Security Numbers
- Medical information (PHI)
- Personal names and addresses
PII masking automatically detects and redacts this information before it reaches the LLM, protecting user privacy and helping you comply with regulations like GDPR, HIPAA, and CCPA.
Prerequisites
Before starting this tutorial, ensure you have:
- Docker installed on your machine
- A LiteLLM API key or OpenAI API key for testing
- Basic familiarity with YAML configuration
curlor a similar HTTP client for testing
Part 1: Deploy Presidio Containers
Presidio consists of two main services:
- Presidio Analyzer: Detects PII in text
- Presidio Anonymizer: Masks or redacts the detected PII
Step 1.1: Deploy with Docker
Create a docker-compose.yml file for Presidio:
version: '3.8'
services:
presidio-analyzer:
image: mcr.microsoft.com/presidio-analyzer:latest
ports:
- "5002:5002"
environment:
- GRPC_PORT=5001
networks:
- presidio-network
presidio-anonymizer:
image: mcr.microsoft.com/presidio-anonymizer:latest
ports:
- "5001:5001"
networks:
- presidio-network
networks:
presidio-network:
driver: bridge
Step 1.2: Start the Containers
docker-compose up -d
Step 1.3: Verify Presidio is Running
Test the analyzer endpoint:
curl -X POST http://localhost:5002/analyze \
-H "Content-Type: application/json" \
-d '{
"text": "My email is john.doe@example.com",
"language": "en"
}'
You should see a response like:
[
{
"entity_type": "EMAIL_ADDRESS",
"start": 12,
"end": 33,
"score": 1.0
}
]
✅ Checkpoint: Your Presidio containers are now running and ready!
Part 2: Configure LiteLLM Gateway
Now let's configure LiteLLM to use Presidio for automatic PII masking.
Step 2.1: Create LiteLLM Configuration
Create a config.yaml file:
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: openai/gpt-3.5-turbo
api_key: os.environ/OPENAI_API_KEY
guardrails:
- guardrail_name: "presidio-pii-guard"
litellm_params:
guardrail: presidio
mode: "pre_call" # Run before LLM call
pii_entities_config:
CREDIT_CARD: "MASK"
EMAIL_ADDRESS: "MASK"
PHONE_NUMBER: "MASK"
PERSON: "MASK"
US_SSN: "MASK"
Step 2.2: Set Environment Variables
export OPENAI_API_KEY="your-openai-key"
export PRESIDIO_ANALYZER_API_BASE="http://localhost:5002"
export PRESIDIO_ANONYMIZER_API_BASE="http://localhost:5001"
Step 2.3: Start LiteLLM Gateway
litellm --config config.yaml --port 4000 --detailed_debug
You should see output indicating the guardrails are loaded:
Loaded guardrails: ['presidio-pii-guard']
✅ Checkpoint: LiteLLM Gateway is running with PII masking enabled!
Part 3: Test PII Masking
Let's test the PII masking with various types of sensitive data.
Test 1: Basic PII Detection
- Request with PII
- What LLM Receives
- Response
curl -X POST http://localhost:4000/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-1234" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "My name is John Smith, my email is john.smith@example.com, and my credit card is 4111-1111-1111-1111"
}
],
"guardrails": ["presidio-pii-guard"]
}'
The LLM will receive the masked version:
My name is <PERSON>, my email is <EMAIL_ADDRESS>, and my credit card is <CREDIT_CARD>
{
"id": "chatcmpl-123abc",
"choices": [
{
"message": {
"content": "I can see you've provided some information. However, I noticed some sensitive data placeholders. For security reasons, I recommend not sharing actual personal information like credit card numbers.",
"role": "assistant"
},
"finish_reason": "stop"
}
],
"model": "gpt-3.5-turbo"
}
Test 2: Medical Information (PHI)
curl -X POST http://localhost:4000/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-1234" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "Patient Jane Doe, DOB 01/15/1980, MRN 123456, presents with symptoms of fever."
}
],
"guardrails": ["presidio-pii-guard"]
}'
The patient name and medical record number will be automatically masked.
Test 3: No PII (Normal Request)
curl -X POST http://localhost:4000/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-1234" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "What is the capital of France?"
}
],
"guardrails": ["presidio-pii-guard"]
}'
This request passes through unchanged since there's no PII detected.
✅ Checkpoint: You've successfully tested PII masking!
Part 4: Advanced Configurations
Blocking Sensitive Entities
Instead of masking, you can completely block requests containing specific PII types:
guardrails:
- guardrail_name: "presidio-block-guard"
litellm_params:
guardrail: presidio
mode: "pre_call"
pii_entities_config:
US_SSN: "BLOCK" # Block any request with SSN
CREDIT_CARD: "BLOCK" # Block credit card numbers
MEDICAL_LICENSE: "BLOCK"
Test the blocking behavior:
curl -X POST http://localhost:4000/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-1234" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [
{"role": "user", "content": "My SSN is 123-45-6789"}
],
"guardrails": ["presidio-block-guard"]
}'
Expected response:
{
"error": {
"message": "Blocked PII entity detected: US_SSN by Guardrail: presidio-block-guard."
}
}
Output Parsing (Unmasking)
Enable output parsing to automatically replace masked tokens in LLM responses with original values:
guardrails:
- guardrail_name: "presidio-output-parse"
litellm_params:
guardrail: presidio
mode: "pre_call"
output_parse_pii: true # Enable output parsing
pii_entities_config:
PERSON: "MASK"
PHONE_NUMBER: "MASK"
How it works:
- User Input: "Hello, my name is Jane Doe. My number is 555-1234"
- LLM Receives: "Hello, my name is
<PERSON>. My number is<PHONE_NUMBER>" - LLM Response: "Nice to meet you,
<PERSON>!" - User Receives: "Nice to meet you, Jane Doe!" ✨
Multi-language Support
Configure PII detection for different languages:
guardrails:
- guardrail_name: "presidio-spanish"
litellm_params:
guardrail: presidio
mode: "pre_call"
presidio_language: "es" # Spanish
pii_entities_config:
CREDIT_CARD: "MASK"
PERSON: "MASK"
- guardrail_name: "presidio-german"
litellm_params:
guardrail: presidio
mode: "pre_call"
presidio_language: "de" # German
pii_entities_config:
CREDIT_CARD: "MASK"
PERSON: "MASK"
You can also override language per request:
curl -X POST http://localhost:4000/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-1234" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [
{"role": "user", "content": "Mi tarjeta de crédito es 4111-1111-1111-1111"}
],
"guardrails": ["presidio-spanish"],
"guardrail_config": {"language": "fr"}
}'
Logging-Only Mode
Apply PII masking only to logs (not to actual LLM requests):
guardrails:
- guardrail_name: "presidio-logging"
litellm_params:
guardrail: presidio
mode: "logging_only" # Only mask in logs
pii_entities_config:
CREDIT_CARD: "MASK"
EMAIL_ADDRESS: "MASK"
This is useful when:
- You want to allow PII in production requests
- But need to comply with logging regulations
- Integrating with Langfuse, Datadog, etc.
Part 5: Monitoring and Tracing
View Guardrail Execution on LiteLLM UI
If you're using the LiteLLM Admin UI, you can see detailed guardrail traces:
- Navigate to the Logs page
- Click on any request that used the guardrail
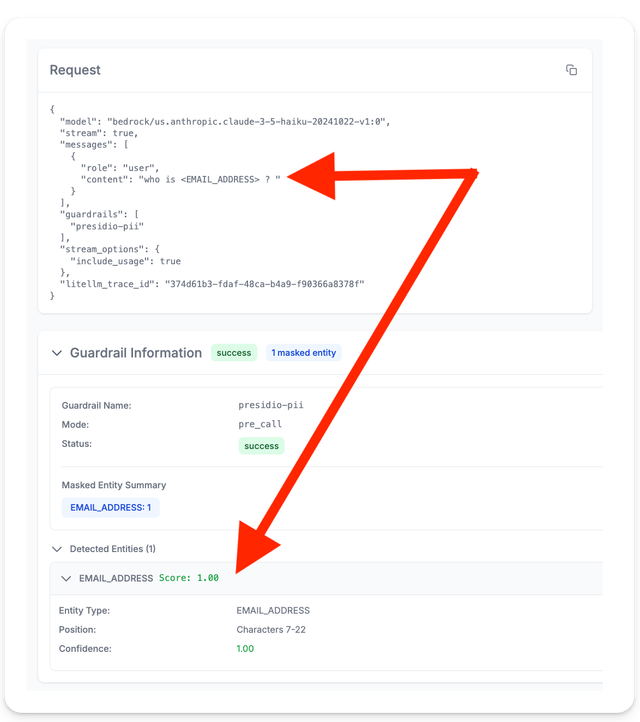
- View detailed information:
- Which entities were detected
- Confidence scores for each detection
- Guardrail execution duration
- Original vs. masked content
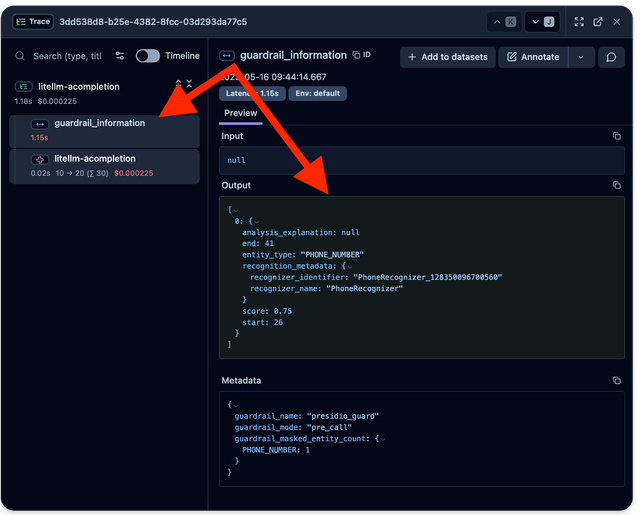
Integration with Langfuse
If you're logging to Langfuse, guardrail information is automatically included:
litellm_settings:
success_callback: ["langfuse"]
environment_variables:
LANGFUSE_PUBLIC_KEY: "your-public-key"
LANGFUSE_SECRET_KEY: "your-secret-key"
Programmatic Access to Guardrail Metadata
You can access guardrail metadata in custom callbacks:
import litellm
def custom_callback(kwargs, result, **callback_kwargs):
# Access guardrail metadata
metadata = kwargs.get("metadata", {})
guardrail_results = metadata.get("guardrails", {})
print(f"Masked entities: {guardrail_results}")
litellm.callbacks = [custom_callback]
Part 6: Production Best Practices
1. Performance Optimization
Use parallel execution for pre-call guardrails:
guardrails:
- guardrail_name: "presidio-guard"
litellm_params:
guardrail: presidio
mode: "during_call" # Runs in parallel with LLM call
2. Configure Entity Types by Use Case
Healthcare Application:
pii_entities_config:
PERSON: "MASK"
MEDICAL_LICENSE: "BLOCK"
US_SSN: "BLOCK"
PHONE_NUMBER: "MASK"
EMAIL_ADDRESS: "MASK"
DATE_TIME: "MASK" # May contain appointment dates
Financial Application:
pii_entities_config:
CREDIT_CARD: "BLOCK"
US_BANK_NUMBER: "BLOCK"
US_SSN: "BLOCK"
PHONE_NUMBER: "MASK"
EMAIL_ADDRESS: "MASK"
PERSON: "MASK"
Customer Support Application:
pii_entities_config:
EMAIL_ADDRESS: "MASK"
PHONE_NUMBER: "MASK"
PERSON: "MASK"
CREDIT_CARD: "BLOCK" # Should never be shared
3. High Availability Setup
For production deployments, run multiple Presidio instances:
version: '3.8'
services:
presidio-analyzer-1:
image: mcr.microsoft.com/presidio-analyzer:latest
ports:
- "5002:5002"
deploy:
replicas: 3
presidio-anonymizer-1:
image: mcr.microsoft.com/presidio-anonymizer:latest
ports:
- "5001:5001"
deploy:
replicas: 3
Use a load balancer (nginx, HAProxy) to distribute requests.
4. Custom Entity Recognition
For domain-specific PII (e.g., internal employee IDs), create custom recognizers:
Create custom_recognizers.json:
[
{
"supported_language": "en",
"supported_entity": "EMPLOYEE_ID",
"patterns": [
{
"name": "employee_id_pattern",
"regex": "EMP-[0-9]{6}",
"score": 0.9
}
]
}
]
Configure in LiteLLM:
guardrails:
- guardrail_name: "presidio-custom"
litellm_params:
guardrail: presidio
mode: "pre_call"
presidio_ad_hoc_recognizers: "./custom_recognizers.json"
pii_entities_config:
EMPLOYEE_ID: "MASK"
5. Testing Strategy
Create test cases for your PII masking:
import pytest
from litellm import completion
def test_pii_masking_credit_card():
"""Test that credit cards are properly masked"""
response = completion(
model="gpt-3.5-turbo",
messages=[{
"role": "user",
"content": "My card is 4111-1111-1111-1111"
}],
api_base="http://localhost:4000",
metadata={
"guardrails": ["presidio-pii-guard"]
}
)
# Verify the card number was masked
metadata = response.get("_hidden_params", {}).get("metadata", {})
assert "CREDIT_CARD" in str(metadata.get("guardrails", {}))
def test_pii_masking_allows_normal_text():
"""Test that normal text passes through"""
response = completion(
model="gpt-3.5-turbo",
messages=[{
"role": "user",
"content": "What is the weather today?"
}],
api_base="http://localhost:4000",
metadata={
"guardrails": ["presidio-pii-guard"]
}
)
assert response.choices[0].message.content is not None
Part 7: Troubleshooting
Issue: Presidio Not Detecting PII
Check 1: Language Configuration
# Verify language is set correctly
curl -X POST http://localhost:5002/analyze \
-H "Content-Type: application/json" \
-d '{
"text": "Meine E-Mail ist test@example.de",
"language": "de"
}'
Check 2: Entity Types
Ensure the entity types you're looking for are in your config:
pii_entities_config:
CREDIT_CARD: "MASK"
# Add all entity types you need
View all supported entity types
Issue: Presidio Containers Not Starting
Check logs:
docker-compose logs presidio-analyzer
docker-compose logs presidio-anonymizer
Common issues:
- Port conflicts (5001, 5002 already in use)
- Insufficient memory allocation
- Docker network issues
Issue: High Latency
Solution 1: Use during_call mode
mode: "during_call" # Runs in parallel
Solution 2: Scale Presidio containers
deploy:
replicas: 3
Solution 3: Enable caching
litellm_settings:
cache: true
cache_params:
type: "redis"
Conclusion
Congratulations! 🎉 You've successfully set up PII masking with Presidio and LiteLLM. You now have:
✅ A production-ready PII masking solution
✅ Automatic detection of sensitive information
✅ Multiple configuration options (masking vs. blocking)
✅ Monitoring and tracing capabilities
✅ Multi-language support
✅ Best practices for production deployment
Next Steps
- View all supported PII entity types
- Explore other LiteLLM guardrails
- Set up multiple guardrails
- Configure per-key guardrails
- Learn about custom guardrails
Additional Resources
Need help? Join our Discord community or open an issue on GitHub!